Abstract
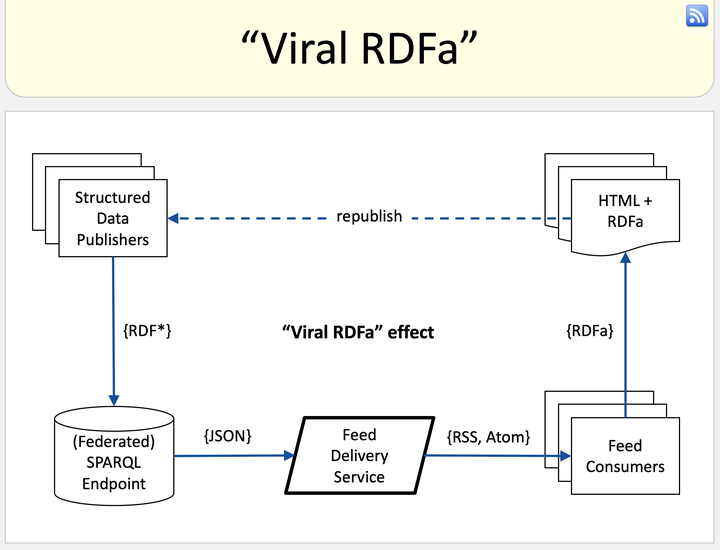
For typical Web developers, it is complicated to integrate content from the Semantic Web to an existing Web site. On the contrary, most software packages for blogs, content management, and shop applications support the simple syndication of content from external sources via data feed formats, namely RSS and Atom. In this paper, we describe a novel technique for consuming useful data from the Semantic Web in the form of RSS or Atom feeds. Our approach combines (1) the simplicity and broad tooling support of existing feed formats, (2) the precision of queries against structured data built upon common Web vocabularies like schema.org, GoodRelations, FOAF, SIOC, or VCard, and (3) the ease of integrating content from a large number of Web sites and other data sources of RDF in general. We also (4) provide a pattern for embedding RDFa into the feed content in a “viral” way so that the original URIs of entities are included in all Web pages that republish the original content and that those pages will link back to the original content. This helps prevent the proliferation of identifiers for entities and provides a simple means for tracking the document URI at which particular content reappears.